
Under våren 2020 gjorde vi en kartläggning av landets kommunrobotar för dels Dagens Samhälle och dels Algorithm Watch. I en av robotarna hittade vi känsliga personuppgifter i källkoden: Trellebergs socialtjänstrobot Ernst1 innehöll ett par hundra personnummer och namn på kommuninvånare. Det här är en genomgång av vad och hur vi gjorde, för den som själv vill gräva i källkoden till beslutsalgoritmer och automatiseringsrobotar.
- Algorithm Watch: Central authorities slow to react as Sweden’s cities embrace automation of welfare management
- DS: Känsliga uppgifter spreds via kod till biståndsrobot
- DS: Professor dömer ut socialtjänstrobot: ”Låter helt galet”
- DS: Därför finns personuppgifter i biståndsroboten
- DS: Trelleborg anmäler personuppgiftsläcka
Flera kommuner har automatiserat delar av biståndshandläggningen, men Trelleborgs kommun har fått mycket uppmärksamhet för att de dels var tidigt ute, och dels införde ett system som kunde fatta beslut själv. En medborgare kan få avslag på en ansökan om bistånd utan att någon människa tittat på den.
I februari 2020 slog kammarrätten fast att källkoden till Ernst ska betraktas som en allmän, offentlig handling, efter att journalisten Freddi Ramel (Tredje Statsmakten) begärt ut källkoden, fått avslag och drivit fallet vidare. Vi begärde ut koden strax därefter.
Ord som ”beslutsalgoritmer”, ”robotar” och ”AI” används i dag om så många olika saker, att en robot som Ernst hade kunnat vara nästan vad som helst mellan en enkel fomulär-validering (”har användaren fyllt i sin personnummer rätt?”), och ett helt maskinlärningssystem (mata en dator med tusentals tidigare ansökningar och lär den känna igen mönster i vilka ansökningar som släpps igenom. Och håll tummarna för att det inte funnits någon systematisk diskriminering i träningsdatan som nu förstärkts och skapat ett monster.) Ernst befinner sig någon däremellan. Det är en uppsättning regler, ett ”beslutsträd” som givet ett antal parametrar anting säger ”ja”, ”nej” eller (i två tredjedelar av fallen) skickar ärendet vidare till manuell handläggning.
Vidare är det en så kallad RPA, en robot som i princip försöker simulera det en människa annars skulle ha gjort på en vanlig dator, i sina vanliga program. Den öppnar Excelfiler, klipper och klistrar in personnummer, klickar på knappar i andra program, och så vidare. Tänk på det som ett avancerat Excel-makro, typ. Sådana går att sätta upp utan att skriva en rad programkod. Det finns färdiga system som låter dig spela in ett arbetsflöde, och sedan upprepa det automatiskt. Därför visste vi inte alls vad ”källkoden” skulle bestå av (ett skräddarsytt program? En regelsamling till något befintligt RPA-system?). Trelleborgs kommun visste inte heller, utan lät en konsult som jobbat med systemet ta fram vad som skulle lämnas ut.

Ordet ”källkod” är alltså inte helt enkelt helt tydligt definierat i det här sammanhanget, men vad vi fick var 1272 xml-filer, med 136 728 rader dansk/engelska instruktioner (företaget som byggt Ernst är danskt) till ett RPA. Det är givetvis omöjligt att överblicka en sådan regelsamling med blotta ögat. Antalet ställen där programmet delar sig på olika sätt (if-satser och switch-rader) är över 1 000. Vilket inte är så konstigt; Det är väldigt många saker som ska fyllas i för att du ska kunna söka bidrag i Trelleborgs kommun (eller i någon annan kommun). Få människor skulle gå igenom den processen för att det är roligt.
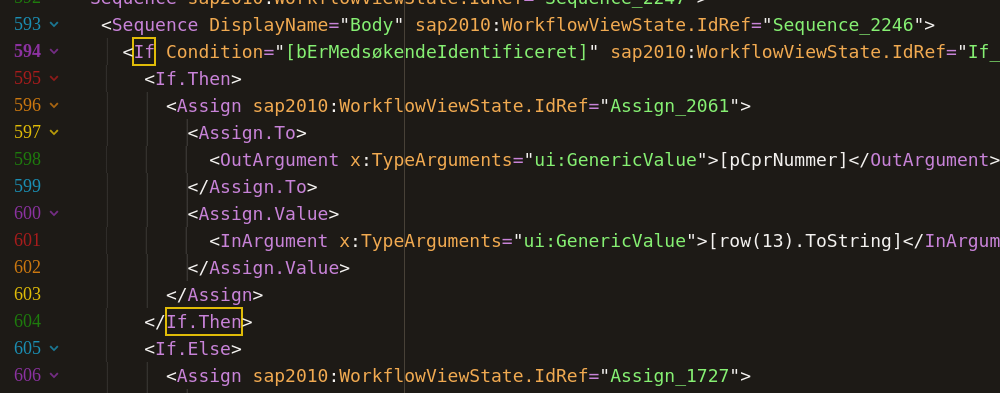
En snabb blick på XML-filerna avslöjar att de skapats inom Microsofts programmeringsramverk .NET, så vi ringde en .NET-utvecklare, Amanuel Workneh i Malmö. Han kunde snabbt identifiera verktyget de skapats med: RPA-plattformen UIPath. Han hjälpte oss också Visualisera programmets alla beslutsvägar. Just detta var vårt intresse; Vi ville veta om det var möjligt för en journalist eller annan medborgare att granska programmets beslutsvägar. Ett antal saker försvårade den analysen: RPA:et baserade beslut på data som hämtade från andra program, till exempel Excel-ark, och det saknades dokumentation som hjälpte oss förstå exakt vilken data som hanterades på olika ställen. Några Excel-filer kunde vi begära ut, och de visade sig i sin tur innehålla viss beräkningslogik. I andra fall fick vi gissa vad variabelnamn som cSambo (i bästa fall) eller pCount (i mindre tursamma fall) kunde tänkas betyda. Inte heller visste vi säkert vilka ”startpunkter” som fanns i beslutskedjan. Vi kan gissa utifrån filnamn och tidsstämplar (senaste ändring) på filerna var vi ska starta någonstans, men det finns mängder ”död” kod, som aldrig nås av programmet. Beror det på att vi fått ut en en soppa av gamla versioner, tester och produktionskod (så ser det ut), eller missar vi sätt koden kan köras på? Återigen gissningar.
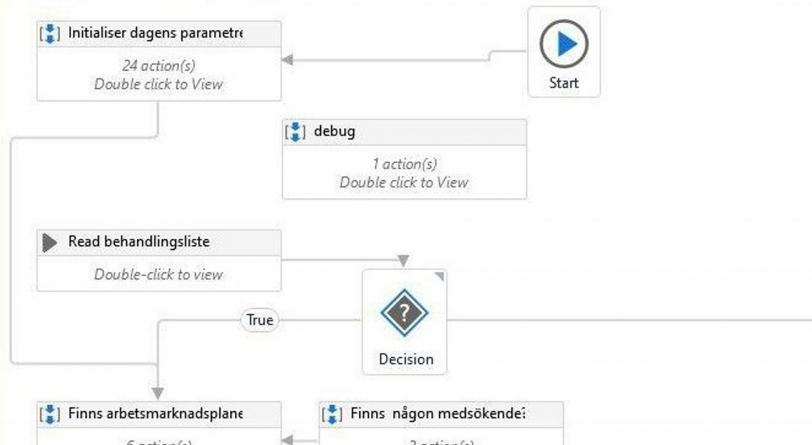
I den här processen hittade vi alltså hundratals personnummer och namn på kommuninvånare i Trelleborg. Att leta efter personnummer i en textmassa kräver inget programmeringskunnande. Det räcker med ett så kallat reguljärt uttryck, en sökning efter ett visst mönster, som kan göras i till exempel Microsoft Word (eller snart sagt vilket textredigeringsprogram som helst). I det här fallet söker vi efter mönstret ”sex siffror, följt av bindestreck, följt av fyra siffror”. Med ett reguljärt uttryck kan det se ut så här: \d{6}-\d{4} (syntaxen skiljer sig lite mellan olika dialekter). 130 000 rader är ungefär dubbelt så många som i Tolstojs Krig och fred, men med reguljära uttryck är det bara ett kontroll-f bort att hitta allt som ser ut som personnummer (knappt 400 stycken), och ur dem sedan sålla ut de faktiska personnumren (knappt 350) och plocka bort dubletter, för en nettolista på 256 personnummer (ännu ett sammanträffande, så vitt vi kan bedöma), de flesta i en lång lista över kunder (med namn, personnummer och något slags ärendedatum) inom hemsjukvården.
När vi först kontaktade kommunen, förstod de själva inte varför det fanns personuppgifter i filerna de skickat, och senare svar var vaga. Men det ser ut som att det finns åtminstone två skäl:
- När en automatisering skapas i UIPath används data som just då finns på skärmen för att bygga hjälp-texter och skärmdumpar. Det är en avsiktlig funktion, något som också framgår av dokumentationen på programmets webbsida. Vi kunde själva enkelt kontrollera det, genom att bygga en egen robot med samma system, och se hur den data som användes vid inspelningen som standard sparades i filerna med regler. I det här fallet handlade det om filer kopplade till ett specifikt ärende som öppnats vid inspelningen.
- En lista med personuppgifter verkar ha använts som testdata. Det stämmer med både tidsstämplar på filerna, och datumuppgifter i själva koden; Listan verkar ha skapats månaden innan systemet togs i bruk.
Det ska nämnas att gränssnittet till mjukvaran kommunen valt att använda har ett peka-och-klicka-gränssnitt, som gör att en icke programmeringskunnig kan bygga en mini-ernst på en kafferast. Det är alltså relativt enkelt att som granskare verifiera en tes om hur programmet beter sig, och vilken information som sparas i regelfilerna.
Listan med testdatan, leder oss över på en annan frågeställning, som får bli ämnet för en kommande granskning: Hur versionshanteras den här typen av programkod, och hur separeras utvecklings- och produktionsmiljöer? Programvaruutvecklare arbetar regelmässigt i versionshanteringssystem (vi på J++, och många andra datajournalister, gör likadant med data). Det gör det möjligt att se hur koden såg ut vid en given tidpunkt, till exempel när ett visst ärende avgjordes av roboten. Här lyckades vi aldrig få besked från Trelleborgs kommun. XML-filerna vi fick ut gav intryck av en miljö där olika versioner av koden låg sida vid sida. För kommande algoritmgranskningar är versionshanteringen en bra standardfråga att alltid ha med sig.
Fotnoter
1 Kommunen kallar den inte så, åtminstone inte utåt, men den är så den heter i all mjukvarukod.
2 Som datajournalist blir man alltid misstänksam när man får ut t.ex. 127, 128, 255 eller 256 av något, eftersom det emellanåt händer att databasutdrag, API-svar etc trunkeras vid 2ⁱ eller 2ⁱ-1. Vi har varit med om det mer än en gång. Men här verkar det vara ett sammanträffande.